1 相关理论
1.1 卷积神经网络与特征提取
卷积神经网络中的卷积层能够很好地描述数据的局部特征,通过池化层可以进一步提取出局部特征中最具有代表性的部分。
由于大部分后门脚本为绕过防护软件的检测会采用字符串拼接、符号编码等方式对代码进行混淆,因此相关脚本在较短的执行周期内,容易出现重复或是相似的指令。
传统的静态检测通过匹配特征码、特征值、危险函数函数来检测恶意。该方法只能检测已知的恶意脚本,并且误报率、漏报率会比较高。但是如果规则完善,可以降低误报率,但是漏报率必定会有所提高。而卷积神经网络已经在图像和语音识别中被证明可以出色地完成此类特征提取的任务。
基于以上分析,本文尝试引入卷积神经网络模型来解决恶意脚本检测的问题。
1.2 Opcode 调用序列
Opcode 是计算机指令中的一部分,用于指定要执行的操作,指令的格式和规范由处理器的指令规范指定。除了指令本身以外通常还有指令所需要的操作数,可能有的指令不需要显式的操作数。这些操作数可能是寄存器中的值,堆栈中的值,某块内存的值或者 IO 端口中的值等等。通常 Opcode 还有另一种称谓:字节码(Byte-code)。
PHP 是构建在 Zend 虚拟机(Zend VM)之上的,PHP 中的 Opcode 则属于字节码。VLD(Vulcan Logic Dumper)是一个在 Zend 引擎中,以挂钩的方式实现的用于输出PHP脚本生成的中间代码(执行单元)的 PHP 扩展。因此我们使用 VLD 提取样本中的 Opcodes。
以目前国内较为常见的 PHP 后门“一句话木马”为例:
<?php @eval($_POST['password']);?>
代码 1:一句话木马
使用 VLD 对其进行 Opcodes 提取,部分输出结果如下所示:
op return operands
-----------------------------------------------
BEGIN_SILENCE ~0
FETCH_R $1 '_POST'
FETCH_DIM_R $2 $1, 'password'
INCLUDE_OR_EVAL $2, EVAL
END_SILENCE ~0
RETURN 1
代码 2:VLD 对于该木马的输出结果
2 基于 Opcodes 序列和 CNN 的 PHP 代码分类模型
本平台对外提供 RESTful API 以接收待检测的目标文件。若当前已存在训练好的检测模型,则加载该模型,否则根据已有的所有训练样本重新训练新的模型。模型加载完成后,将对得到的目标文件进行预处理。预处理的过程由 preprocess() 函数负责,平台整体的检测流程如下:
BEGIN
Receive testing file through RESTful API
IF exist CNN model
Restore the model from disk
ELSE
Train a new CNN model with dataset
Save the model into disk
END IF
Preprocess testing files
Check with the existing CNN model
Return the result and the odds for testing files
END
代码 3: Webshell 检测平台检测流程的伪代码
2.1 模型的输入处理
BEGIN
FOR every file in fileset
Get opcodes from specified file
Convert opcode symbols to numeric sequence
Add the sequence into resultset
END FOR
Find the max length of all sequences
FOR every sequence in resultset
Padding the sequence to specified length
Update resultset
END FOR
Return resultset
END
代码 4:preprocess() 函数的伪代码
输入数据由样本 Opcodes 列表和所对应的标签两部分组成。Opcodes 通过 PHP 的 VLD 扩展进行提取,并将得到的字符串序列按调用次序存储于列表中。每组 Opcodes 序列对应一个二值的标签(0 为白样本,1 为恶意样本),即 PHP 代码所属的分类。
php_path = '/usr/bin/php'
cmd = ('{0} -dvld.active=1 -dvld.execute=0'.format(php_path)).split()
cmd.append(filename)
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
代码 5: 调用 VLD 扩展
上述 1.2 节中的 PHP 后门所对应的 Opcodes 序列如下:
['BEGIN_SILENCE', 'FETCH_R', 'FETCH_DIM_R', 'INCLUDE_OR_EVAL', 'END_SILENCE', 'RETURN']
得到 Opcodes 字符串序列后需对其进行序列化,以适应模型卷积层的输入。此处按照 PHP 官方的 Opcodes 列表将其转换为相应的数字序列:
[36, 109, 95, 134, 73, 188]
for index, code in enumerate(codes_seq):
if not code_record.count(code):
codes_seq[index] = 0
continue
codes_seq[index] = code_record.index(code) + 1
代码 6: Opcodes 序列化过程
由于所采用的卷积层接受输入的维度需保持一致,假设已知 Opcodes 序列的最大长度为 m,当前待处理的序列长度为 l,则在当前序列尾部填充 m - l 个 0。
max_length = len(reduce(lambda x, y: x if len(x) > len(y) else y, codes_seqs))
代码 7: 寻找最大的序列长度
最后对测试样本所属的标签进行二类化转换:
0 -> [1, 0]
1 -> [0, 1]
def to_categorical(y):
y = np.asarray(y, dtype='int32')
Y = np.zeros((len(y), 2))
Y[np.arange(len(y)), y] = 1.
return Y
代码 8: to_categorical() 函数
2.2 模型的具体结构
本文所采用的卷积神经网络的具体结构如图所示。
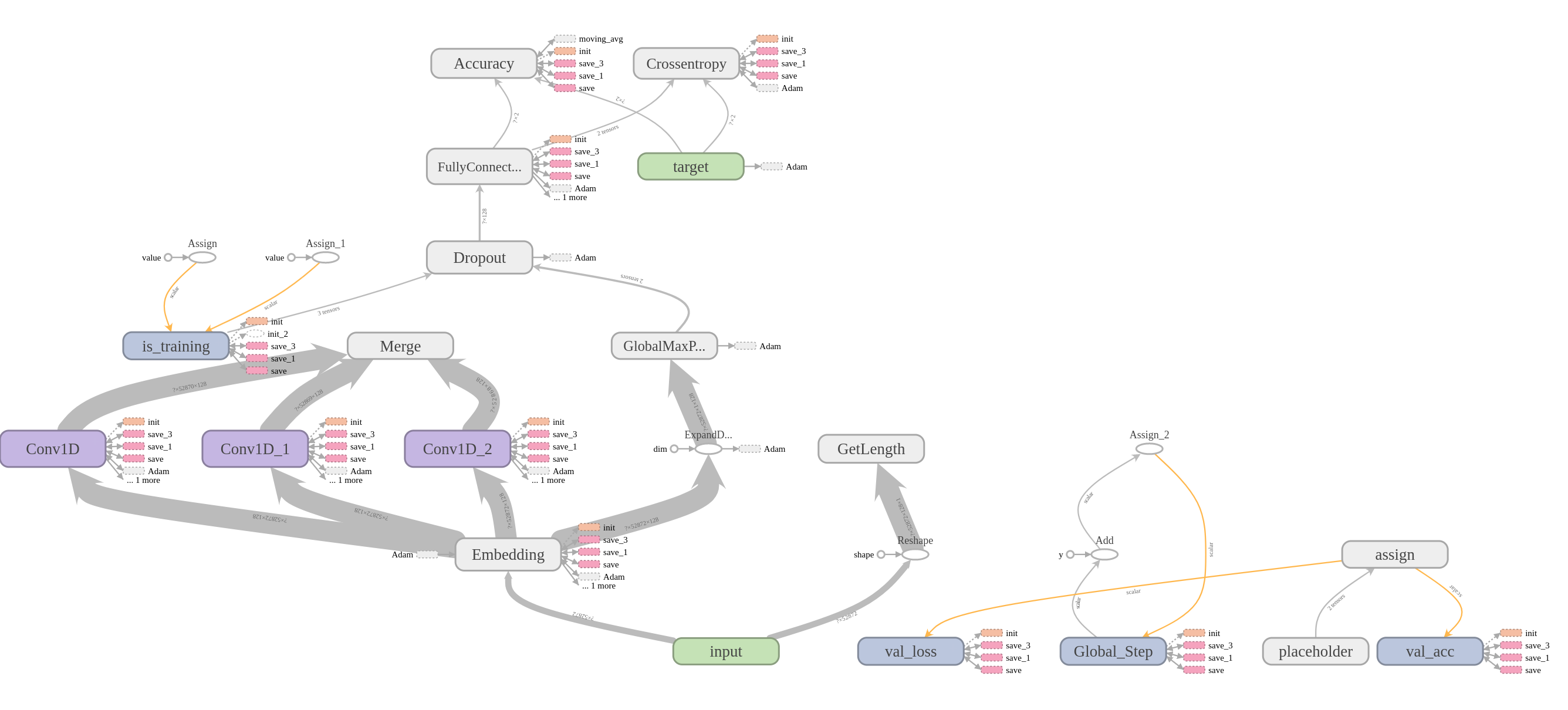
图 1 本文 CNN 模型结构
卷积层由三种长度分别为 3、4、5 的一维卷积核组成,用以对输入的 Opcodes 序列进行特征提取。为尽可能充分地考虑到每个 Opcode 指令的执行上下文,从而提取出不同粒度大小的局部特征,本文采用了 3 x 128、4 x 128、5 x 128 三种不同大小的卷积核结构。同时,为了加快训练收敛速度,采用 ReLu 函数作为激活函数。
\[f(x) = max(0, x)\]随后的池化层(global_max_pool)提取出每组 Opcodes 序列中最具有代表性的特征。为了减少过拟合的情况,在输出层之前加入通过 dropout 对输入神经元的输入进行 1 / 0.8 倍放大。
最后通过全连接层(fully_connected)来输出二维的分类结果,完成 Opcodes 序列到代码分类的映射。使用 Softmax 函数作为全连接层的激活函数:
\[softmax(x)_i = \frac{exp(x_i)}{\sum_j{exp(x_j)}}\]2.3 模型的训练
本文采用基于多类的交叉熵函数作为损失函数:
\[H(p, q) = -\sum_x p(x) \log q(x)\]使用 Adam 优化算法,以 0.001 的学习速率最小化交叉熵。Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
3 模型训练与评估
3.1 运行环境
本文中的所有模型测试均在如表 1 所示的运行环境中完成。
| 运行环境 | 环境配置 |
|---|---|
| 操作系统 | Ubuntu 16.04 |
| CPU | Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz |
| 显卡 | GeForce GTX 1060 6G |
| 内存 | 15G + 15G (swap) |
| 编程语言 | Python 3.5 |
| 深度学习框架 | tensorflow 1.4.0 |
表 1:运行环境及配置
3.2 数据集的选择与处理
实验数据来自于 Github 上部分知名开源 PHP 项目和 Webshell 收集项目。该数据集中总共包含 2648 个样本,其中白样本 1394 个,恶意样本 1254 个。使用留出法对上述两种样本按照 4:1 的比例进行划分,并对样本顺序进行随机调整以减小其对训练结果的干扰,用以对模型预测的准确率与召回率进行评估。划分后的训练集与测试集中的样本数量分别为 1986 与 662。
数据集划分完成后,还需要对其进行一系列的预处理:
a) 提取 Opcodes。使用 PHP 的 VLD 扩展,以对 Zend 引擎添加挂钩的方式输出 PHP 脚本生成的中间代码(执行单元),并存储于列表中。
b) 对 Opcodes 进行序列化。将所有已提取出的 Opcodes 字符串序列按照官方的 Opcodes 列表转换为相应的数字序列。
c) 填充 Opcodes 序列。由于所采用的卷积层接受输入的维度需保持一致,因此需要先遍历所有已知 Opcodes 序列以获取出最大的序列长度。然后将所有的 Opcodes 序列填充至同一长度。
d) 二类化样本标签。所使用模型中全连接层的输出维度为二维,因此需要对测试样本的标签进行相应的转换。
3.3 模型训练
采用 Tensorflow 作为深度学习引擎的后端,使用 tflearn 框架进行神经网络的构建。使用测试集对模型进行 10 轮迭代训练,学习率为 0.001。其中关键代码如下:
# 参数 seq_max_len 为已知 Opcodes 序列的最大长度
network = tflearn.input_data(shape=[None, seq_length], name='input')
# 定义 CNN 模型:
# 卷积层(使用 3 个数量为 128,长度分别为 3、4、5 的一维卷积函数处理数据)
network = tflearn.embedding(network, input_dim=seq_length, output_dim=128)
branch1 = tflearn.layers.conv.conv_1d(network, 128, 3, padding='valid', activation='relu', regularizer='L2')
branch2 = tflearn.layers.conv.conv_1d(network, 128, 4, padding='valid', activation='relu', regularizer="L2")
branch3 = tflearn.layers.conv.conv_1d(network, 128, 5, padding='valid', activation='relu', regularizer="L2")
tflearn.layers.merge_ops.merge([branch1, branch2, branch3], mode='concat', axis=1)
# 将卷积层的输出维度增加至二维
network = tf.expand_dims(network, 2)
# 池化层
network = tflearn.layers.conv.global_max_pool(network)
# 为减少过拟合,在输出层之前对神经元的输出进行处理
network = tflearn.layers.core.dropout(network, 0.8)
# 全连接层
network = tflearn.fully_connected(network, 2, activation='softmax')
# 定义损失函数与优化器
network = tflearn.layers.estimator.regression(network, optimizer='adam', learning_rate=0.001, loss='categorical_crossentropy')
# 实例化 CNN 模型对象并进行训练数据,此处进行 10 轮
model = tflearn.DNN(network)
model.fit(x_train, y_train, n_epoch=10, shuffle=True, validation_set=0.1, batch_size=100)
3.3 检测结果
混淆矩阵如下:
| 预测结果 | ||
|---|---|---|
| 真实情况 | 恶意 | 正常 |
| 恶意 | 314 | 11 |
| 正常 | 38 | 299 |
表 2: 检测结果的混淆矩阵
评估指标如下:
| 项目 | 结果 |
|---|---|
| 精确率(Precision) | 0.8872 |
| 召回率(Recall) | 0.9645 |
| 综合评价指标(F-score) | 0.9243 |
计算公式如下:
\[precision = \frac{TP}{TP + FP}\] \[recall = \frac{TP}{TP + FN}\] \[\text{F-score} = 2 \frac{precision \times recall}{precision + recall}\]公式 1: 评估指标公式
通过 TensorBoard 得到了模型训练过程中准确率(Accuracy)以及交叉熵(Loss)的变化情况:
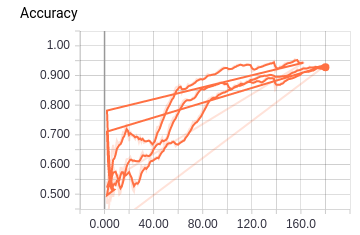
图 2: 准确率变化曲线
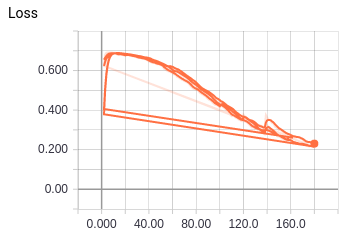
图 3: 交叉熵变化曲线
参考资料
- https://segmentfault.com/a/1190000011112448
- http://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CJFQ&dbname=CJFDLAST2016&filename=JSYJ201610006&uid=WEEvREcwSlJHSldRa1FhcTdWZDhML2VjWFFSRUs4eGJvZ0dJbVRsQXczQT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4ggI8Fm4gTkoUKaID8j8gFw!!&v=MTg5NTJGeXJrVnJ2Skx6N1NaTEc0SDlmTnI0OUZZb1I4ZVgxTHV4WVM3RGgxVDNxVHJXTTFGckNVUkwyZVp1UnY=
- http://www.php-internals.com/book/?p=chapt02/02-03-02-opcode
- https://www.jiqizhixin.com/articles/2017-07-12
- https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。